1.1 Overfitting
overfitting occurs when our model fits nearly perfectly to our training data, However, fitting to closely to test data isn’t always a good thing.
模型在训练集表现完美,但是在测试集中表现不好,我们就说模型过拟合了
Markdown Latex数学公式 https://blog.csdn.net/fzch_struggling/article/details/44998901
1.2 Types of Regularization
1.2.1 L1&L2 Regularization
L1&L2 regularization用来惩罚大的权重
L2正则化
L1正则化
1.2.2 Cross Validation
1.2.3 Early Stopping

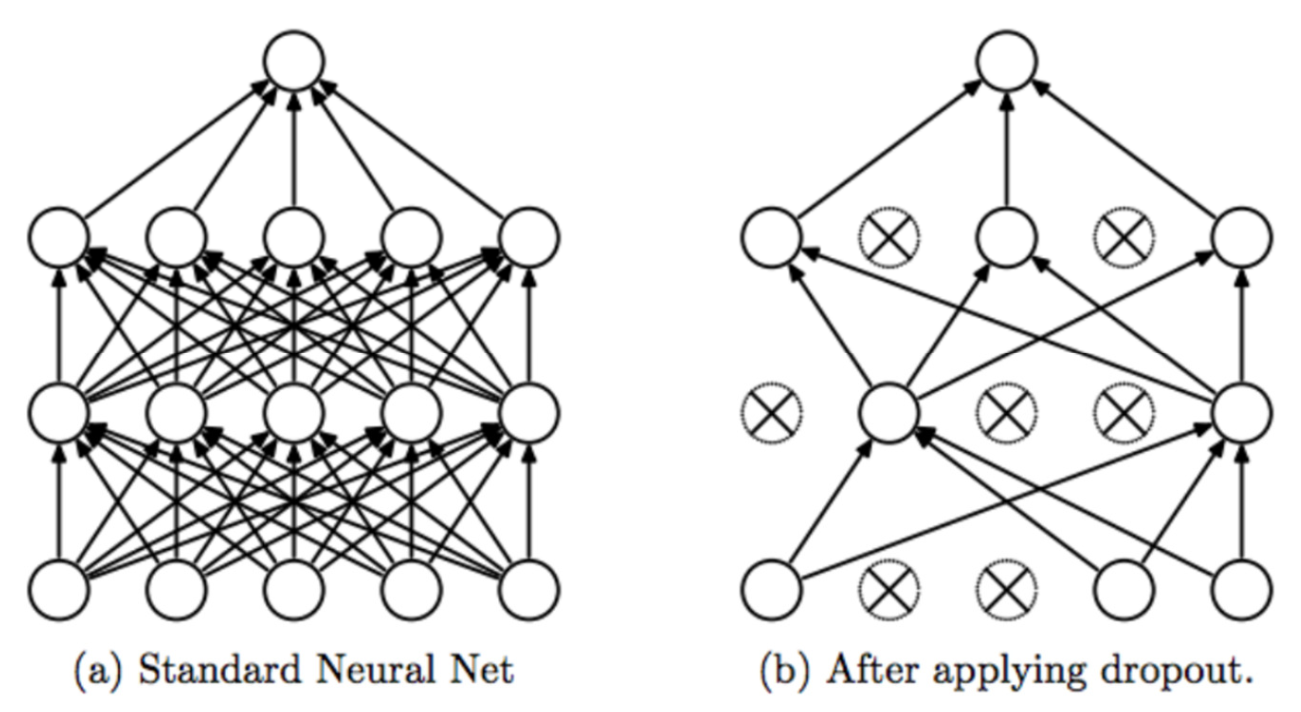
1.2.4 Dropout
Dropout 用于降低神经元之间的依赖性,在Dropout中,设定参数‘p’表示了保留节点的概率,(1-p)是哪些被丢掉的,dropout几乎使得训练的收敛时间翻倍
1.2.5 Data Augmentation
数据增强只是简单地将输入数据集的数据做简单的变换以便获得更多的数据量去做训练